I am pursuing my PhD in the School of Artificial Intelligence at Xi’an Jiaotong University (XJTU),
with research affiliations at the State Key Laboratory of Human-Machine Hybrid Augmented Intelligence,
the National Engineering Research Center for Visual Information and Applications,
and the Institute of Artificial Intelligence and Robotics.
My research lies at the intersection of world-model-centric embodied AI, autonomous driving, and vision-language-action (VLA) systems.
I’m particularly interested in how latent world models, long-horizon control, and diffusion-based planning can be combined to make robot policies reliable, temporally consistent, and deployable on real platforms.
Previously, I worked on world-model and perception systems at Baidu Apollo (ADFM), Alibaba DAMO Academy, and Huawei Noah’s Ark Lab, and I am now founding an embodied-intelligence startup, Cytoderm Intelligent Technology.
Research Overview
My long-term goal is to build world-model-first autonomous robotics capable of robust long-horizon reasoning, dexterous manipulation, and real-world deployment.
Methodologically, my work spans:
World Models & Generative Planning
Latent 3D / video world models, diffusion-based planners, and chunked action policies for long-horizon control in manipulation and driving.
Vision-Language-Action (VLA) for Robotics
World-model-centric VLA architectures for generalizable robotic behavior, including dexterous grasping and manipulation tasks with action chunking, seam-aware execution, and RL fine-tuning over large-scale, unstructured robotic data.
Autonomous Driving & 3D Perception
Semi-supervised BEV 3D detection, panoramic surround-view sensing, uncertainty-aware localization, and HD map construction for embodied navigation.
On the application side, my work has been validated on large-scale robotic manipulation benchmarks such as CALVIN, LIBERO, and real-world robotic platforms, as well as autonomous-driving datasets including nuScenes, KITTI-360, and Waymo.
Huazhong University of Science and Technology (HUST)
2017 – 2019
Expertise
Embodied AI & Robot Learning (2025 – Present)
World models, VLA policies, diffusion-based planners, chunked and hierarchical control.
Autonomous Driving & 3D Perception (2020 – 2025)
BEV 3D detection, surround-view fisheye perception, HD map construction, planning under uncertainty.
Computer Vision & Machine Learning (2013 – 2019)
Semi-supervised learning, tensor methods, model compression and distillation.
News
2025.12 – Released Cytoderm·Robotic Arm, a lightweight robotic manipulation platform designed for embodied AI research and industrial prototyping. More details: https://www.cytoderm.ai/
2025.12 – Launched Cybopal, a consumer-level embodied-intelligence robot product for everyday interactive and assistive tasks. See product page: https://cybopal.com/
2025.11 – ChunkFlow: Towards Continuity-Consistent Chunked Policy Learning completed and under review at a top venue in robot learning / AI.
2025.10 – Object-Guided Semi-Supervised BEV 3D Object Detection with 3D Box Refinement accepted by IEEE T-ITS.
2025.09 – Finished large-scale experiments on LIBERO long-horizon manipulation benchmark with world-model-centric VLA agents.
2024.06 – 1st-place solution for CVPR 2024 Autonomous Driving Grand Challenge – Predictive World Model Track.
2024.03 – Multiple works on BEV detection, spherical fusion, and map construction accepted to CVPR / ACM MM.
Publications
A more complete and up-to-date list is available on Google Scholar.
Recent works (2025–2024)
Under review
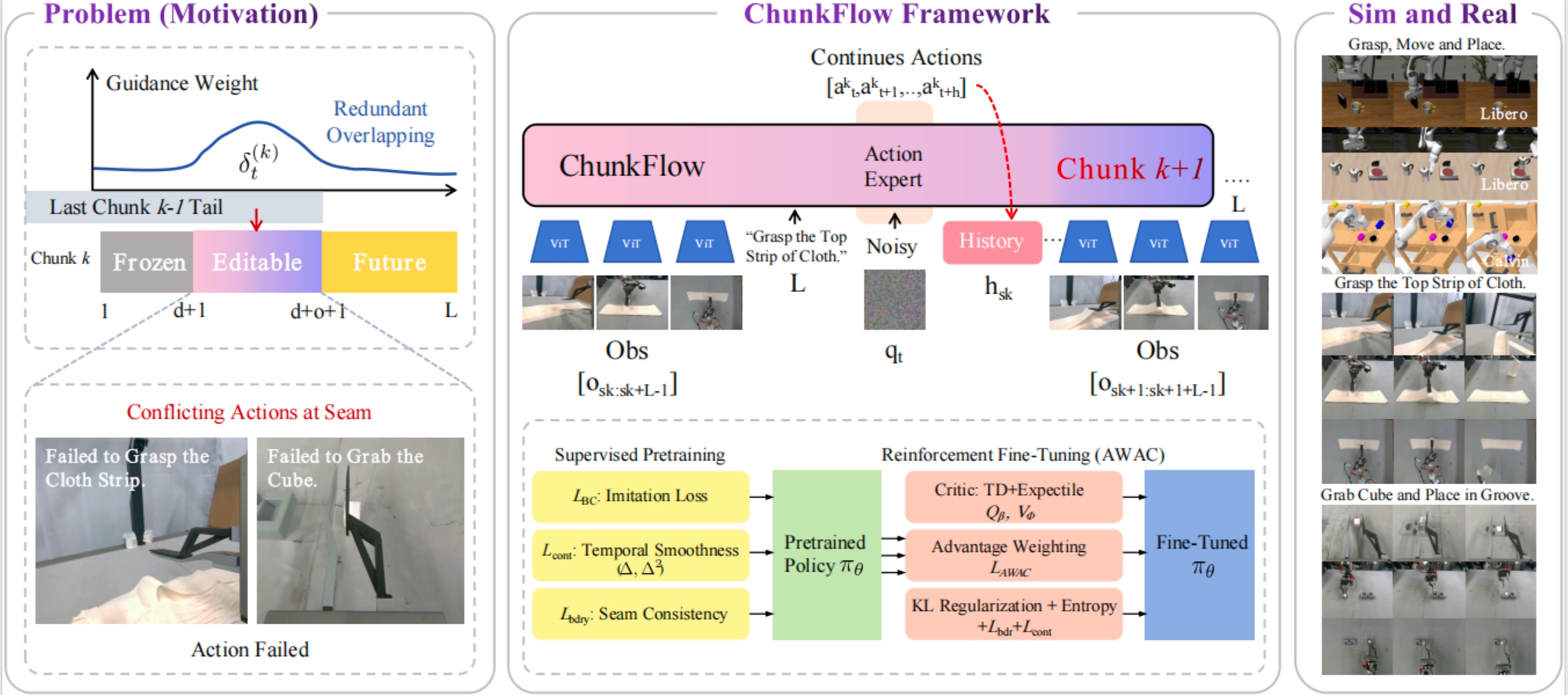
ChunkFlow: Towards Continuity-Consistent Chunked Policy Learning
Zhao Yang, Yinan Shi, et al.
Under review, 2025.
VLA policy with chunked actions, overlap blending, and continuity-constrained RL to suppress boundary jitter in long-horizon control.

 Under review
Under review
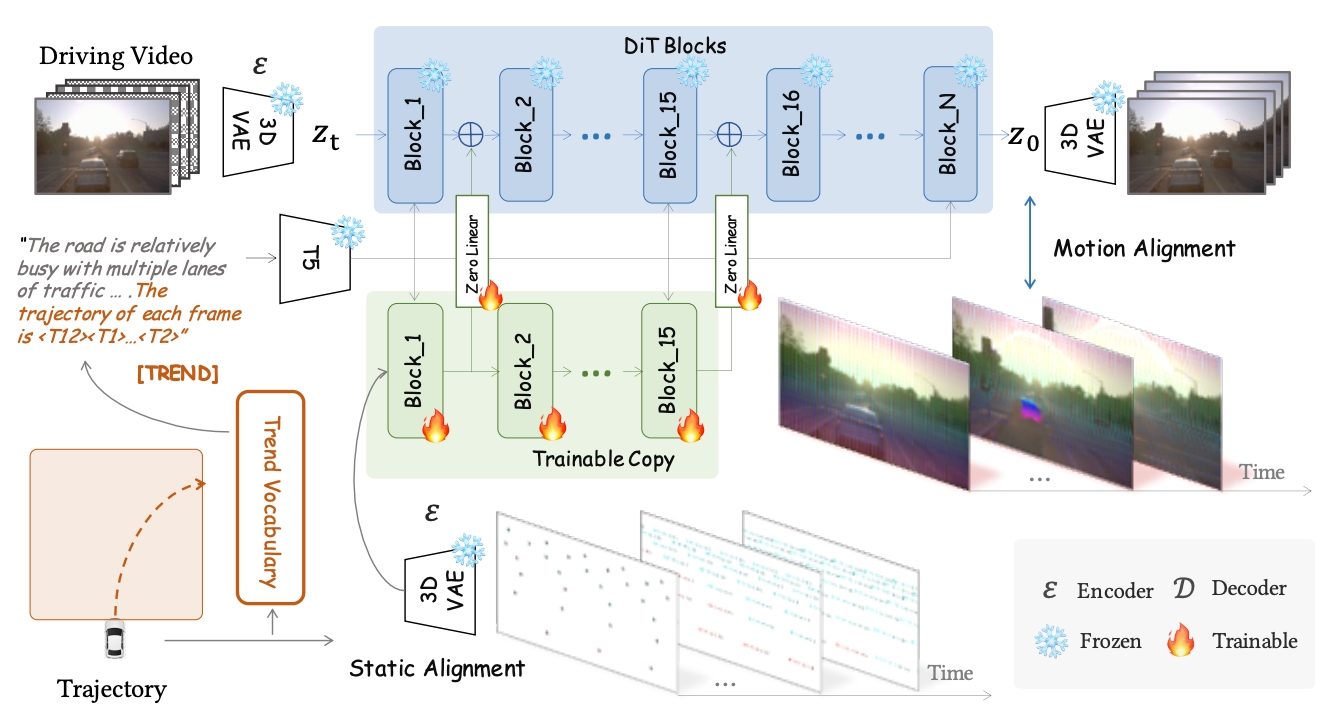 ACM MM 2025
ACM MM 2025
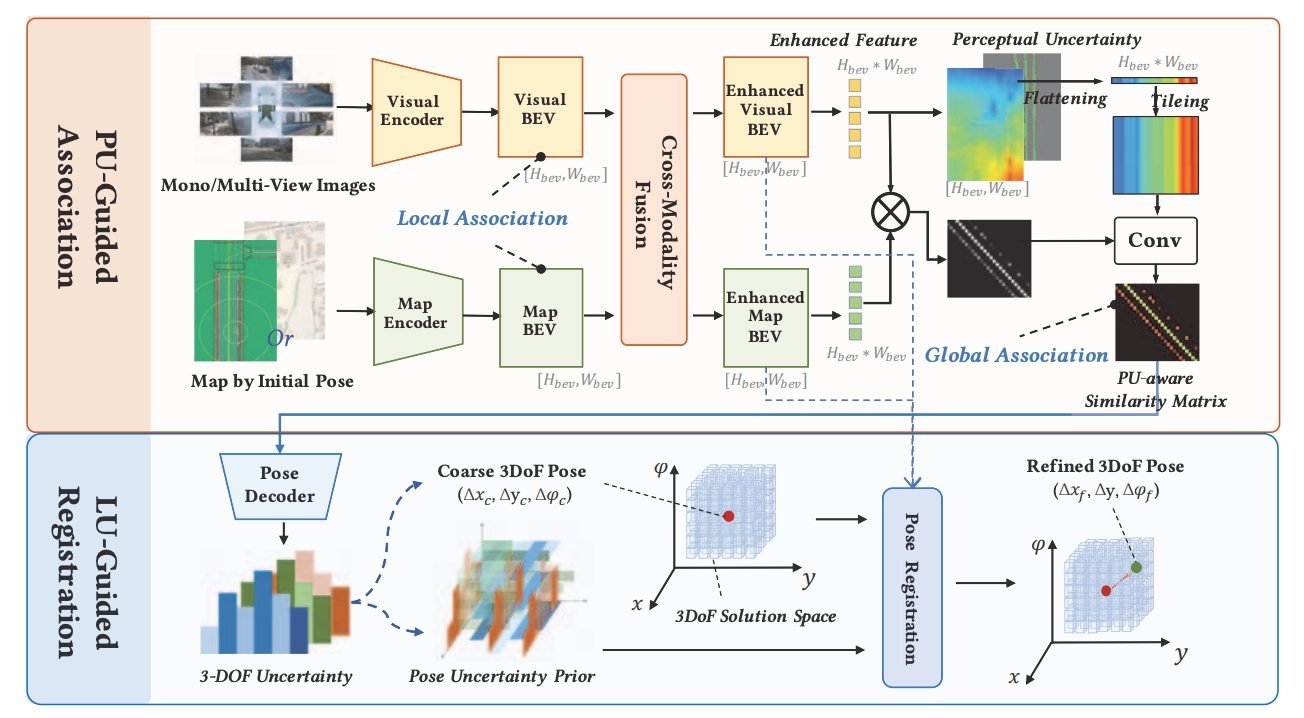 ICCV 2025
ICCV 2025
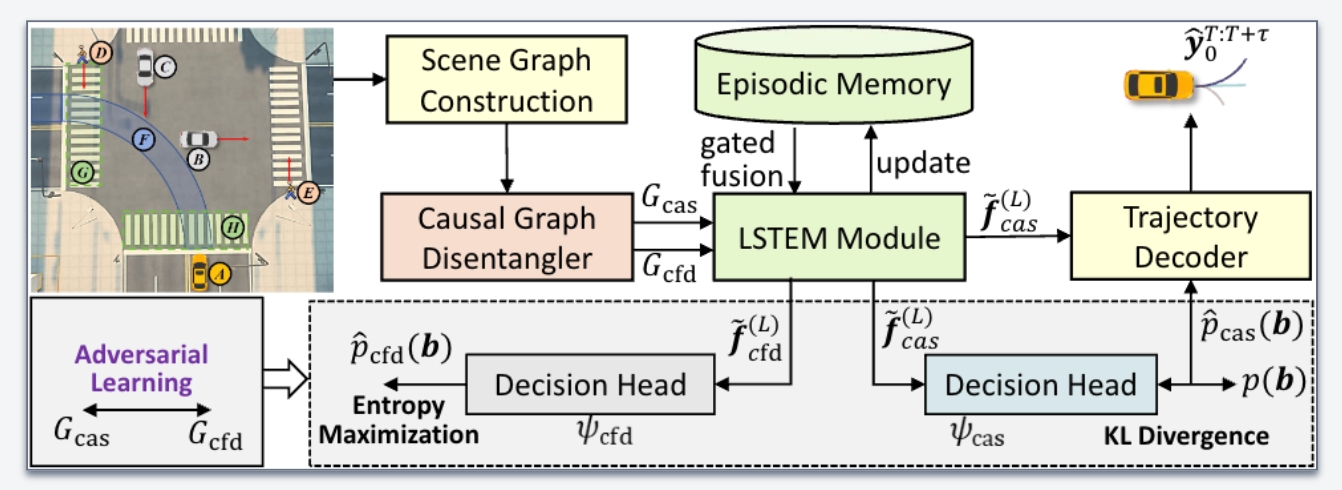 IROS 2025
IROS 2025
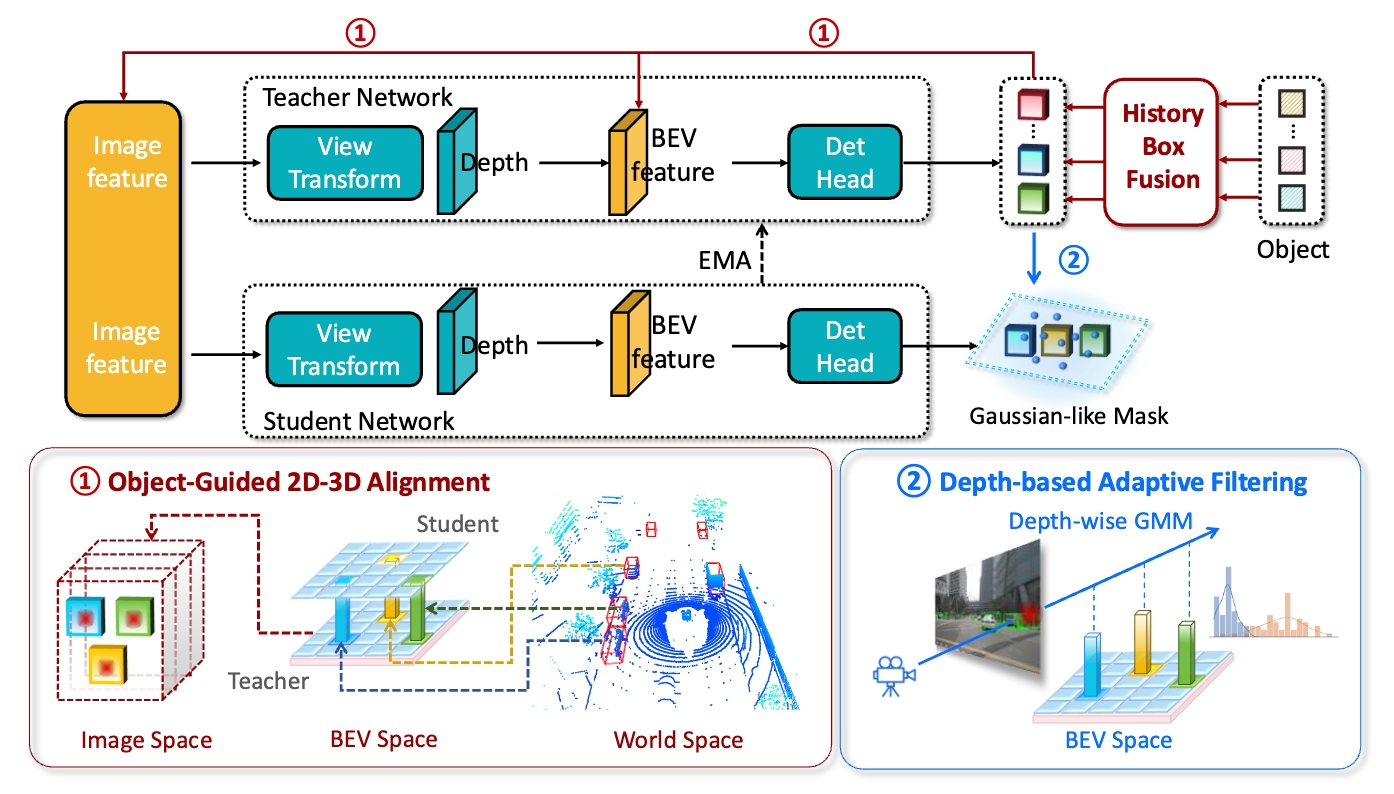
 ICRA 2025
ICRA 2025
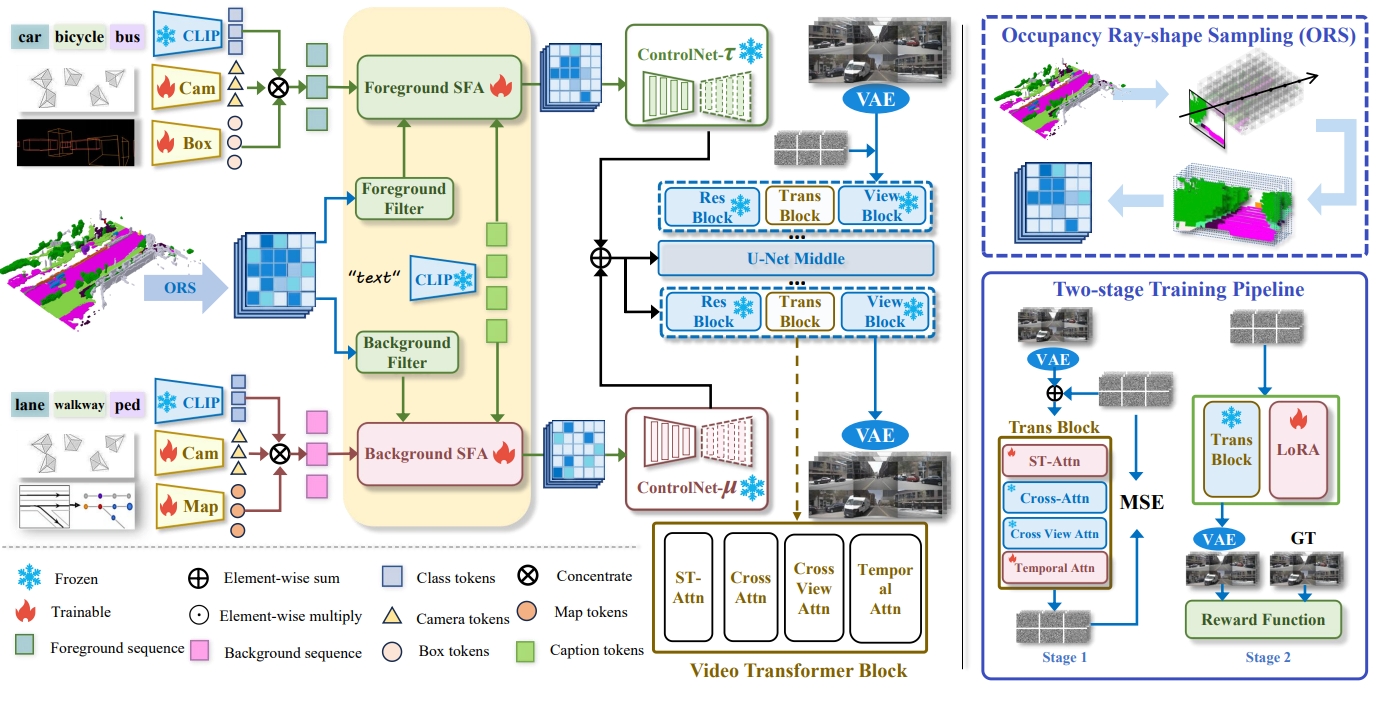 Under Review
Under Review
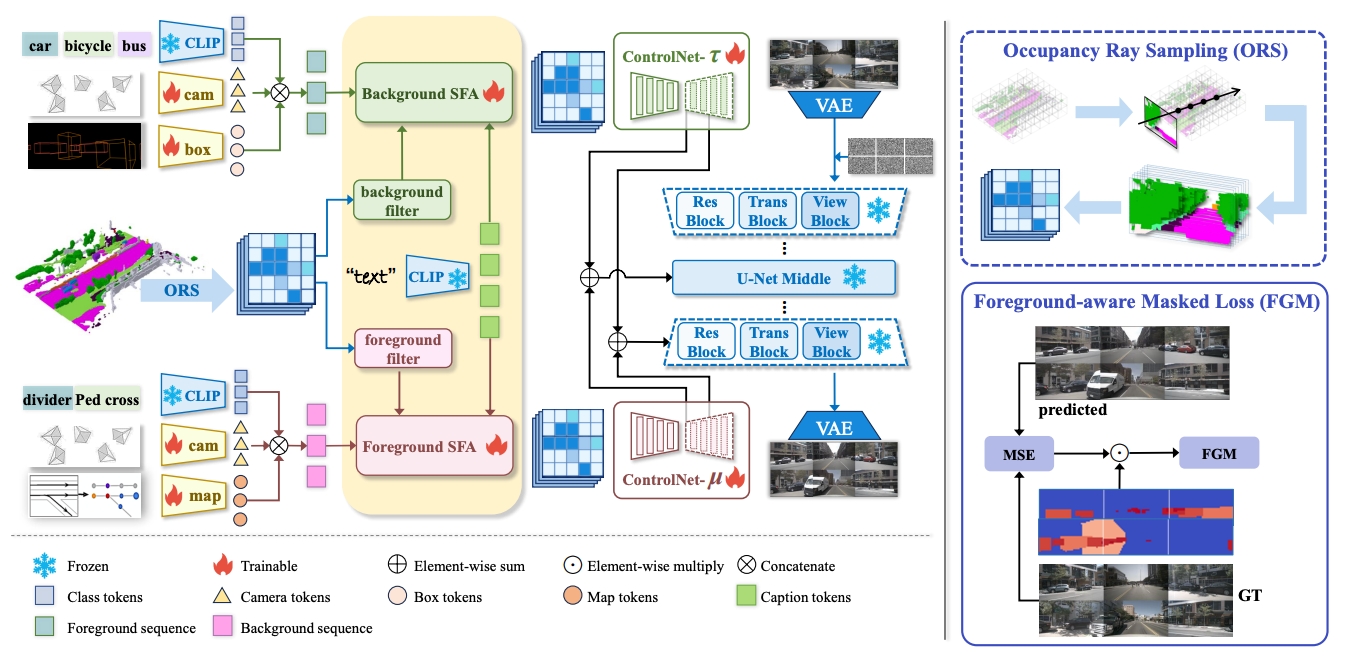 ICRA 2025
ICRA 2025
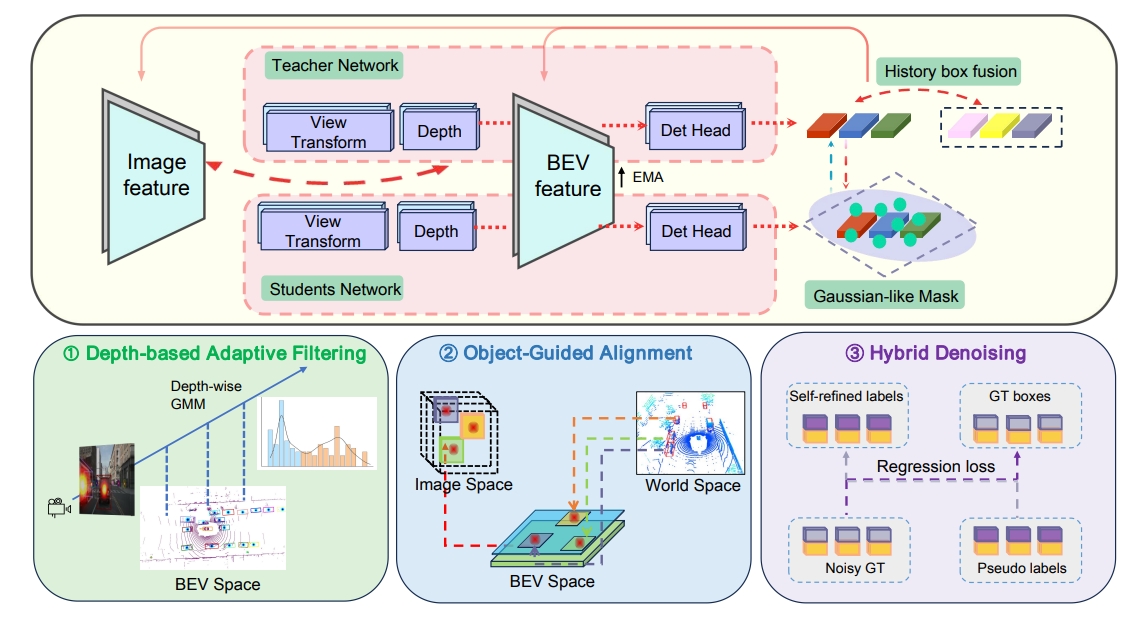
 T-ITS 2025
T-ITS 2025
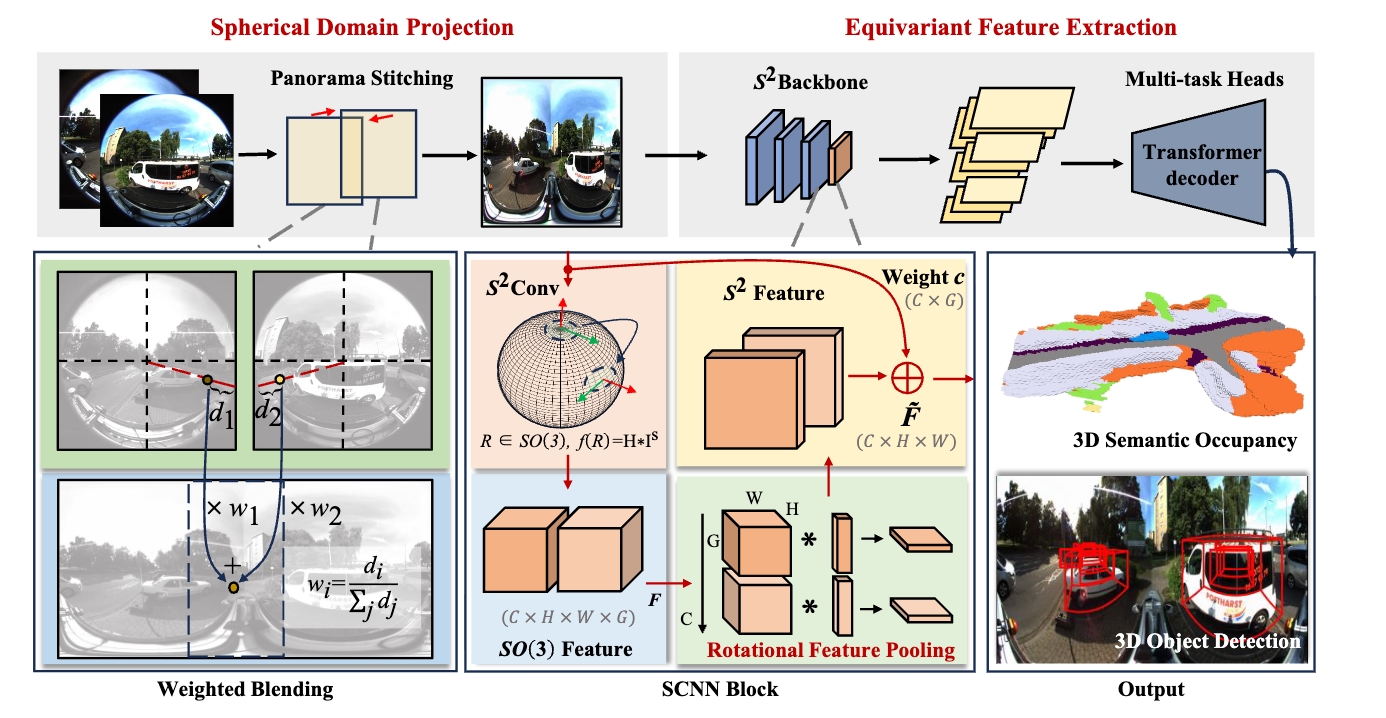 Info Fusion 2025
Info Fusion 2025
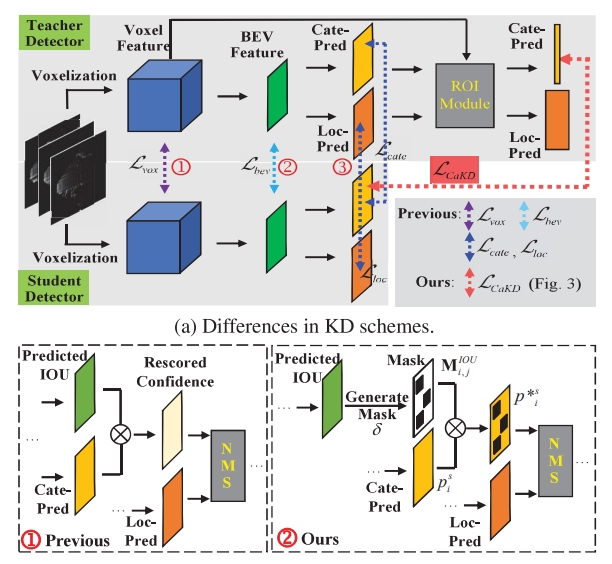 CVPR 2024
CVPR 2024
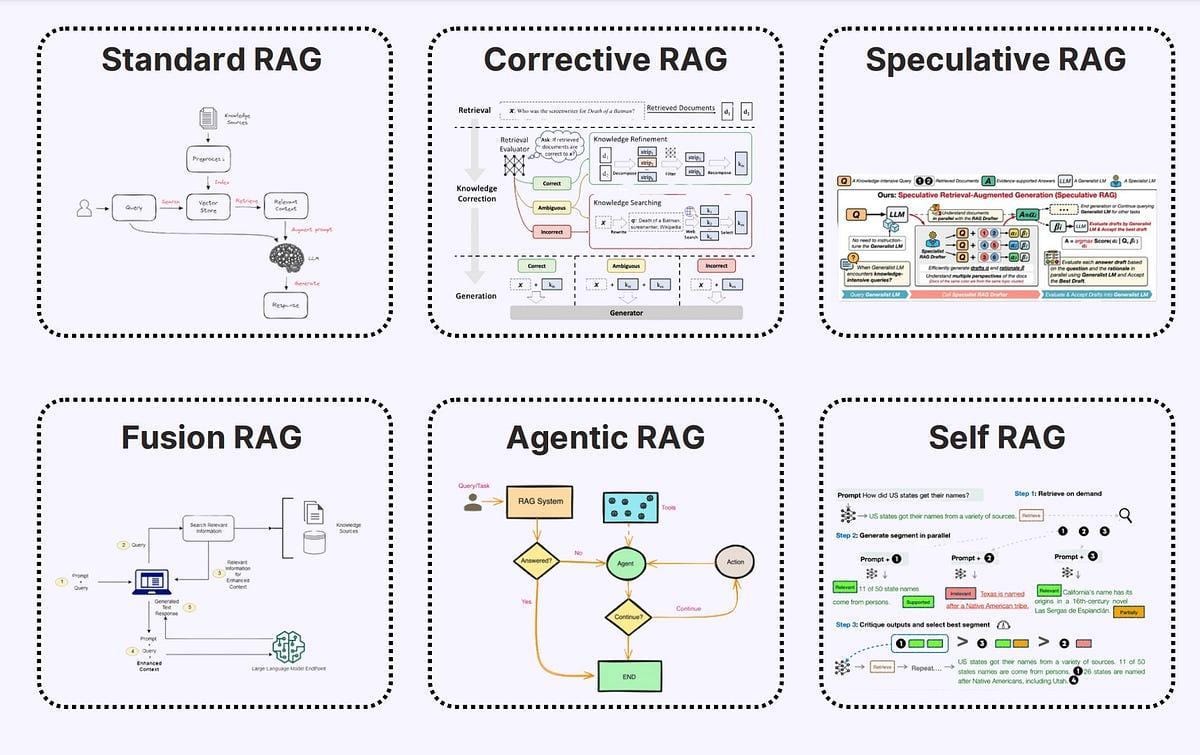 ACM MM 2024
ACM MM 2024
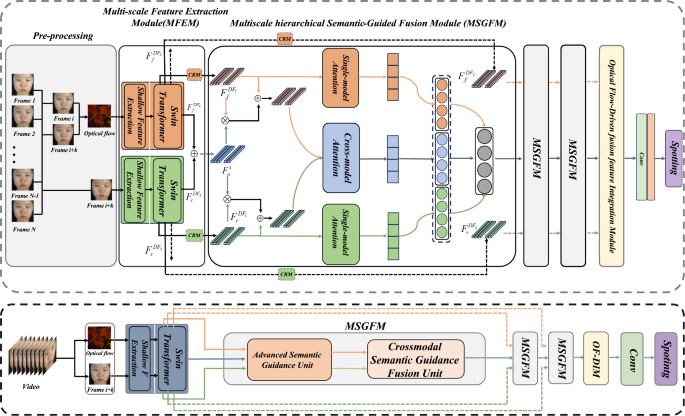 ACM MM 2024
ACM MM 2024
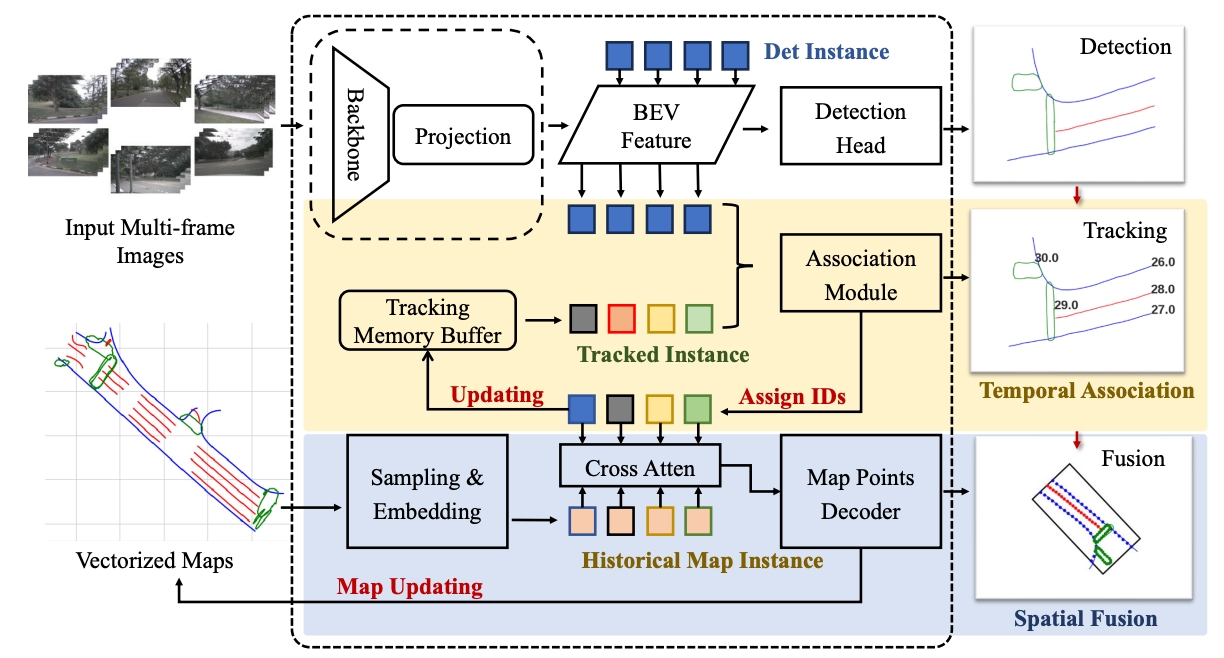 ACM MM 2024
ACM MM 2024
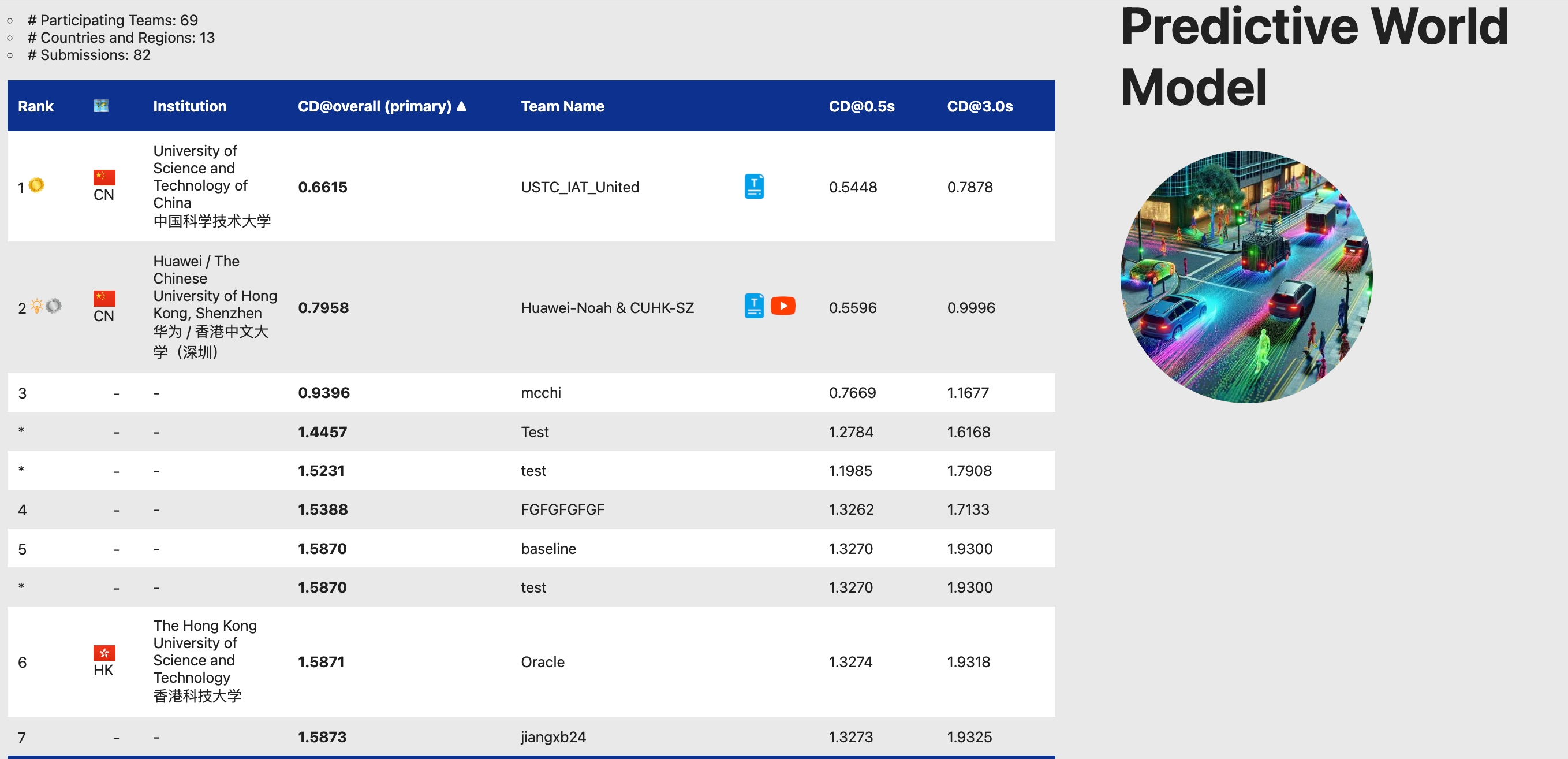 CVPRW 2024 · 1st place
CVPRW 2024 · 1st place
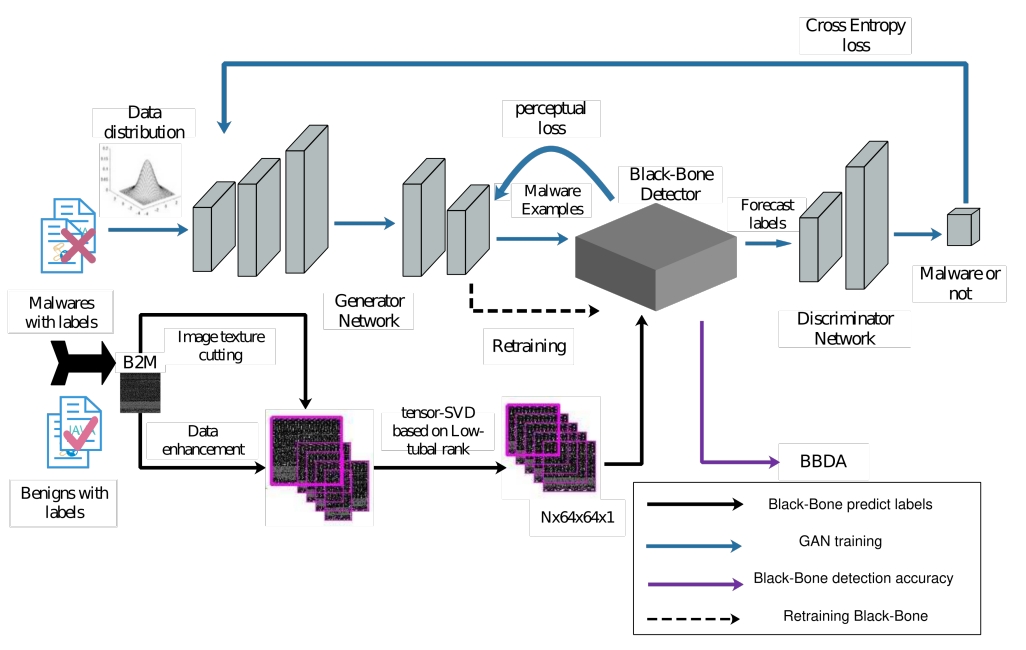 Journal 2022
Journal 2022
 T-CSS 2020
T-CSS 2020
 CVPRW 2020 · 1st place
CVPRW 2020 · 1st place